- انجمن نیویورک 2023
- برگه حقایق: سرمایه گذاری در آمریکا: دولت بایدن هریس تولید را پیش از سرمایه گذاری زیرساخت های اینترنتی تاریخی افزایش می دهد
- مقایسه کارگزار XTB MT4 - CFD های تجاری با سادگی و سهولت
- بازار نفت پایه
- سهام جهانی از آشفتگی بانکی جان سالم به در می برد - اما برای چه مدت؟
- راهنمای گام به گام: سرمایه گذاری در ارزهای دیجیتال برای مبتدیان
- کتابهای QBD
- تجارت انرژی تهدیدات نوسانات را به فرصت ها تبدیل می کند
- تجزیه و تحلیل مخاطبان هدف و تدوین توصیه های مربوط به ترویج لوازم خانگی (یک مورد از جاروبرقی بی سیم بوش نامحدود) < SPAN> تجزیه و تحلیل مخاطبان هدف و تهیه توصیه های ترویج وسایل خانه داری (موردی از جاروبرقی بی سیم بوش نامحدود) تجزیه و تحلیل مخاطبان هدف
- مزیت دستیار هوشمند لاجورد

آخرین مطالب
امکانات وب


هفتاد و پنج سال پیش ، بنیامین گراهام-پدر تجزیه و تحلیل امنیت-نوشت که در کوتاه مدت بازار مانند یک دستگاه رأی گیری رفتار می کند ، اما در طولانی مدت بیشتر شبیه یک ماشین وزنه برداری است. نکته گراهام این بود که ترس ، حرص و آز و سایر احساسات (دستگاه رأی دهی) می تواند نوسانات کوتاه مدت بازار را هدایت کند که به نوبه خود باعث ایجاد ارتباط بین قیمت و ارزش واقعی سهام یک شرکت می شود. با این حال ، در مدت زمان طولانی ، دستگاه توزین به عنوان اصول شرکت در نهایت باعث می شود که ارزش و قیمت بازار سهام آن همگرا شود.
به طور سنتی ، سرمایه گذاران با مطالعه صورتهای درآمدی ، ترازنامه ها و سایر اطلاعات عمومی در مورد عملکرد یک شرکت ، تجزیه و تحلیل اساسی بلند مدت را انجام داده اند. سپس ، آنها از این اطلاعات در زمینه ارزش بازار شرکت استفاده می کنند تا تصمیم آگاهانه در مورد چشم انداز آن به عنوان یک سرمایه گذاری بلند مدت بگیرند.
اتوماسیون این فرآیند ، سرمایه گذاری با ارزش سیستماتیک ، با ظهور داده های با کیفیت بالا در اصول شرکت و قدرت محاسباتی روزافزون در دسترس محققان امکان پذیر شده است. جذابیت یک رویکرد خودکار این است که می توان از تکنیک های آماری دقیق برای ارزیابی هزاران فرصت استفاده کرد ، و یک فرایند سیستماتیک می تواند سرمایه گذاران را از تعصبات رفتاری به خوبی مستند محافظت کند که اغلب از عملکرد سرمایه گذاری جلوگیری می کنند.
در یک نامه سرمایه گذار اخیر ، ما توضیح دادیم که چرا یادگیری عمیق ، و به ویژه شبکه های عصبی مکرر ، ممکن است مناسب استفاده از سرمایه گذاری با ارزش سیستماتیک بلند مدت باشد. این اولین بار در یک سری از پست های وبلاگ است که برخی از اکتشافات ما در این زمینه را توصیف می کند.
زمینه
برنامه های اخیر یادگیری عمیق و شبکه های عصبی مکرر منجر به عملکرد بهتر از انسان توسط رایانه ها در بسیاری از حوزه ها شده است. با این حال ، کار بسیار کمی در استفاده از این فناوری ها در مدیریت سرمایه گذاری وجود داشته است. با این وجود ، دلایل مختلفی وجود دارد که یادگیری عمیق ممکن است نتایج بهتری نسبت به روشهای آماری سنتی یا رویکردهای یادگیری ماشین غیر عمق در هنگام استفاده از سرمایه گذاری طولانی مدت بدست آورد. این دلایل شامل:
- رویکردهای یادگیری ماشین به طور معمول به گونه ای ساخته می شوند که هدف پیش بینی چیزی از تعداد ثابت ورودی ها باشد. با این حال ، در دنیای سرمایه گذاری ، داده های ورودی به طور معمول در توالی ها قرار می گیرند (به عنوان مثال ، چگونه نتایج عملیاتی یک شرکت با گذشت زمان تکامل می یابد) و توزیع نتایج سرمایه گذاری با تکامل آن توالی ها شرط می شود. شبکه های عصبی مکرر ، که در سالهای اخیر موفقیت های زیادی را کسب کرده اند ، دقیقاً برای این نوع داده های توالی طراحی شده اند.
- در زمینه سرمایه گذاری کمی ، تلاش زیادی در "مهندسی فاکتور" قرار می گیرد - روند تعیین ویژگی های یک شرکت برای پیش بینی قیمت سهام آینده خود با ارزش ترین است. Deep Leaing فرصت بالقوه ای را برای اجازه دادن به الگوریتم ها بر اساس داده های مالی خام فراهم می کند. یعنی "عمیق" در یادگیری عمیق به این معنی است که لایه های پی در پی یک مدل قادر به ایجاد روابط مهم به روشی سلسله مراتبی از داده هایی هستند که "در طبیعت" یافت می شود ، و این روابط ممکن است قوی تر از مواردی باشد که از طریق رویکردهای سنتی یافت می شودبه مهندسی فاکتور
- برخی از بزرگترین پیشرفت در یادگیری عمیق در زمینه پردازش متن بوده است. این قابلیت باعث می شود که امکان اعمال استفاده از قسمت عظیم داده های متنی غیر ساختار یافته و کیفی مربوط به شرکت هایی باشد که می توانند در پرونده های SEC ، گزارش های خبری ، پست های وبلاگ ، رسانه های اجتماعی و رونوشت های درآمد یافت شوند.
در تحقیقات ما ، ما در حال بررسی این نوع فرصت های ایجاد شده توسط یادگیری عمیق هستیم.

چرا سرمایه گذاری بلند مدت؟
هنگام استفاده از ریاضیات و فناوری برای سرمایه گذاری ، تمایل به الگوسازی و بهره برداری از فرصت های تجاری کوتاه مدت وجود دارد. بنابراین چرا ما تمرکز خود را بر روی سرمایه گذاری بلند مدت کارگردانی کرده ایم؟در حالی که فرصت های تجاری کوتاه مدت به یک محقق اجازه می دهد تا موفقیت یک مدل را با فرکانس بیشتر آزمایش کند ، چالش با استراتژی های تجارت سهام این است که بسیاریحتی یک چهارماز طرف دیگر ، شواهد آماری خوبی وجود دارد که نشان می دهد ، در طولانی مدت ، اصول در حال تحول یک شرکت نقش اصلی در تعیین ارزش بازار آن دارد. یک نمونه بارز از برنده برنده نوبل رابرت شیلر ، که نشان داد قیمت بورس در طی دوره های کوتاه بسیار بی ثبات است اما با توجه به درآمد آنها در دوره های طولانی تا حدودی قابل پیش بینی است.
راه اندازی
در این پروژه ما از شبکه های عصبی عمیق استفاده کردیم (اصطلاحی که ما برای استفاده از کلاس شبکه های عصبی که شامل Perceptrons چند لایه و شبکه های عصبی مکرر است) استفاده خواهیم کرد تا پیش بینی کنیم که چگونه یک سهام نسبت به بازار طی یک سال یکبار انجام می دهدافقانتخاب افق زمانی فرایندی برای یافتن بهترین تعادل بین داشتن مقدار کافی داده برای یادگیری و داشتن افق کافی است که به اندازه کافی طولانی مدت باشد.
میزان داده های با کیفیت بالا که در حال حاضر می توانید در اصول شرکت های بازار گسترده در حدود 55 سال (از سال 1960 تا 2015) کسب کنید. اگر ما به دنبال پیش بینی عملکرد سهام در یک افق زمانی 5 ساله بودیم ، فرایند یادگیری ما فقط 11 دوره زمانی مستقل خواهد داشت. از طرف دیگر ، اگر افق زمانی ما یک ماه بود ، ما 660 دوره زمانی مستقل خواهیم داشت. اگرچه دوره های مستقل تر برای یادگیری مفید است ، اما دلایلی وجود دارد که معتقدند قیمت ها در دوره های بسیار کوتاه بیش از حد تحت تأثیر عوامل برون زا برای مدل ها بر اساس اصول هستند تا از قدرت پیش بینی کافی برخوردار باشند. بنابراین ما به دنبال یک افق زمانی هستیم که کوچکترین موردی است که می توان آن را به دست آورد. ما در یک افق یک ساله مستقر شدیم.
در این تنظیم ، ما در مراحل زمانی که با فاصله یک ماهه فاصله دارند ، داده ها را به مدل های خود می دهیم. ماهانه بالاترین دانه بندی داده های قیمت گذاری با کیفیت برای سهام قبل از سال 1983 است ، بنابراین این بازه زمانی اساسی است که ما از آن استفاده می کنیم. دلالت بر این است که از این مدل در هر مرحله (ماه) خواسته می شود تا پیش بینی آنچه در قیمت 12 مراحل زمان سهام (یک سال) در آینده رخ خواهد داد ، پیش بینی کند. از نظر بصری ، به نظر می رسد:
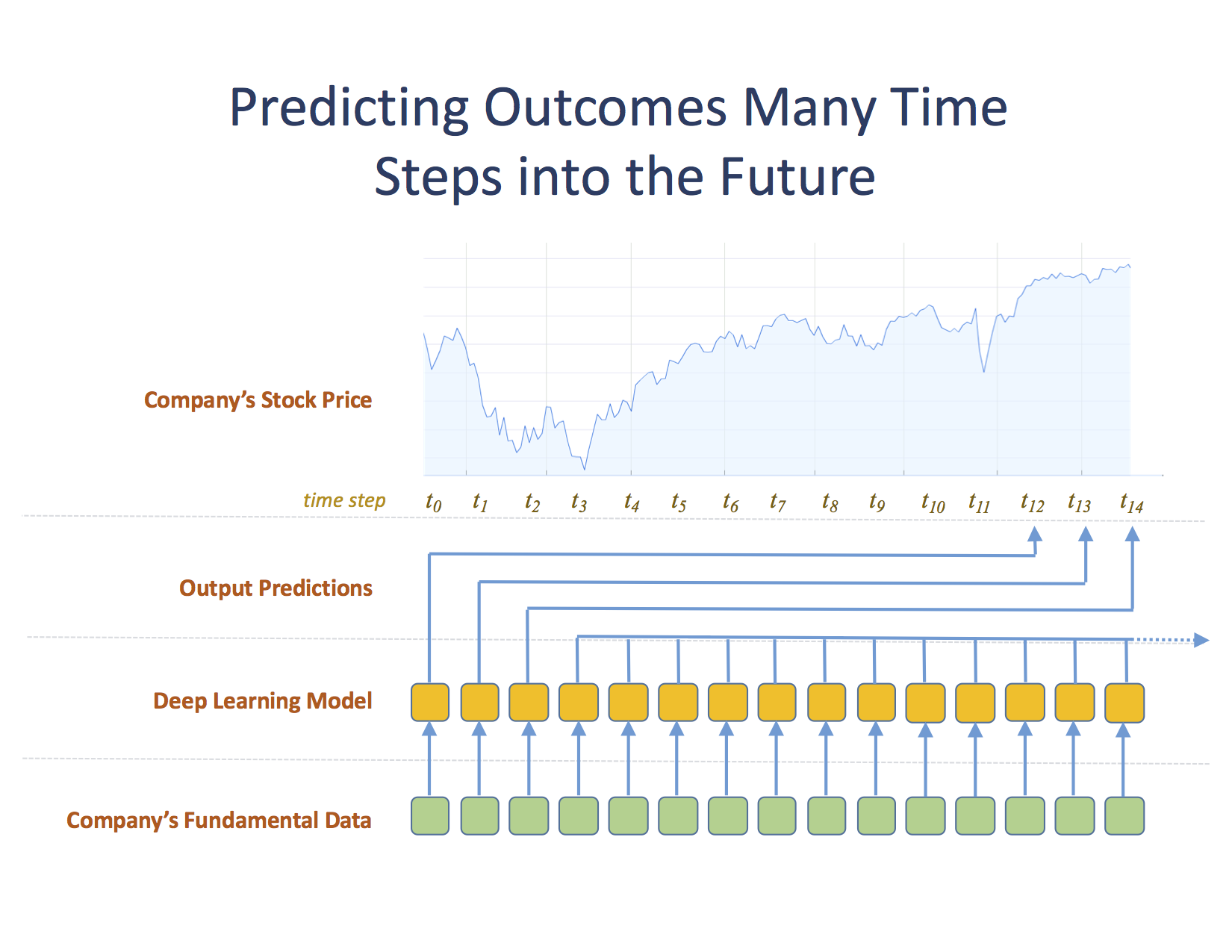
این تنظیم حتی برای شبکه های عصبی مکرر کمی غیرمعمول است. به طور معمول ، ما در تلاش هستیم تا نتیجه ای را در مرحله بعدی پیش بینی کنیم ، یا در تلاش هستیم تا نتیجه ترمینال را پیش بینی کنیم. با این وجود ، ساخت مدل داده برای این روش دشوار نیست. به طور خاص ، ما می خواهیم مجموعه ای از توالی ها را بسازیم که در آن هر دنباله تکامل یک شرکت را در طول زمان نشان می دهد ، و هر عنصر یک دنباله نمایانگر یک شرکت/ماه است (ما این را یک شرکت ماه می نامیم). علاوه بر این ، هر شرکت ماه با نتیجه ای برچسب گذاری می شود ، جایی که نتیجه آن مربوط به نحوه عملکرد سهام شرکت در سال بعد است.
در این تحقیق ، نتیجه را به روشی بسیار ساده الگوبرداری می کنیم. به طور خاص ، اگر تغییر قیمت سهام بیشتر از تغییر متوسط قیمت همه سهام باشد ، ما نتیجه 1+ را به آن اختصاص می دهیم. در غیر این صورت ، نتیج ه-1 است.
این مدل را می توان بصری به عنوان یک جدول که در آن هر ردیف یک ماه شرکت است به تصویر کشید:
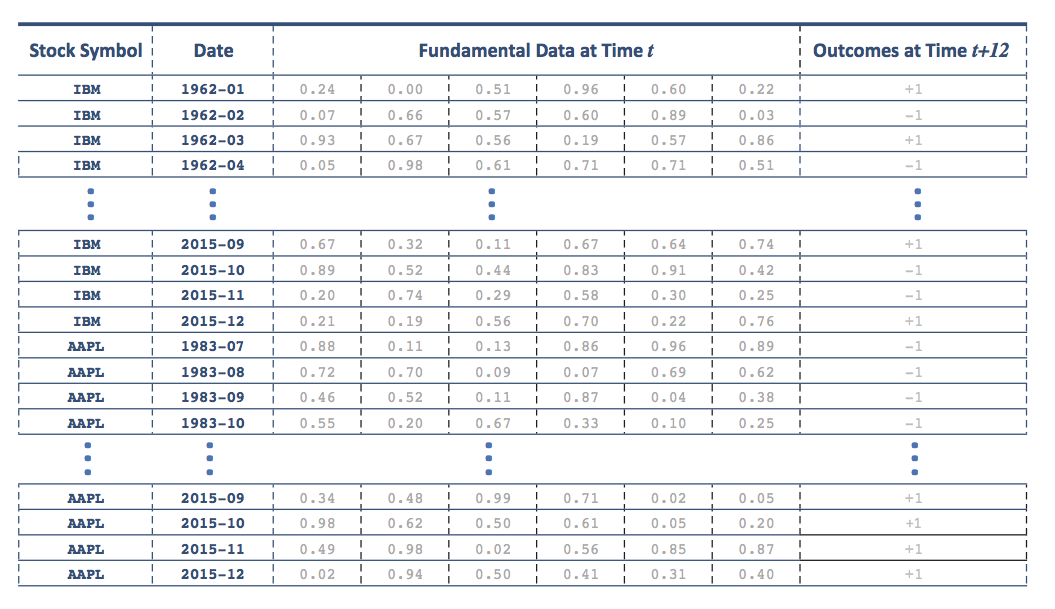
یک انتقاد آشکار از یک پیش بینی ساده دو طبقه این است که ما در حال آموزش مدل نیستیم تا میزان عملکرد خارج از سهام را پیش بینی کنیم. این درست است ، اما ما ادعا می کنیم که: (1) این رویکرد "نوار پایین" ، یادگیری را در مورد داده های اساسی بلند مدت بسیار ساده تر می کند (قابل دستیابی). و (2) ما هنوز هم می توانیم به عملکرد سرمایه گذاری بسیار خوبی برسیم. با آموزش یک مدل برای پیش بینی احتمال اینکه سهام در رده 1+ قرار بگیرد (از سهام متوسط عملکرد متوسط) ، می توانیم از احتمالات خروجی به عنوان معیار اعتماد به نفس استفاده کنیم و سپس ساخت اوراق بهادار سرمایه گذاری را تشکیل دهیم که از شرکت هایی با اعتماد به نفس بالایی برخوردار هستندعملکرد بهترعلاوه بر این ، این تنظیم ساده نقطه شروع را برای رویکردهای تصفیه شده تر ایجاد می کند.
در پست وبلاگ بعدی (قسمت 2) ، ما در مجموعه داده هایی که برای آموزش این مدل استفاده می کردیم ، به تفصیل خواهیم پرداخت.< SPAN> این مدل را می توان بصری به عنوان یک جدول که در آن هر ردیف یک ماه شرکت است نشان داد:
گزینه های باینری...
ما را در سایت گزینه های باینری دنبال می کنید
برچسب : نویسنده : سحر زکریا بازدید : 37
